18 Lines of the Powerful Request Generator with Python (asyncio/aiohttp)
A simple script to generate a huge amount of requests. Python 3.7 + asyncio + aiohttp.
18 Lines of Code
This is the smallest properly working HTTP client based on asynio/aiohttp (Python 3.7) that generates the maximum possible number of requests from your personal device to a server. You can use this template however you wish, e.g. to crawl the web or to test your servers against DoS attacks (denial-of-service).
On GitHub: https://github.com/fadeevab/18-lines-request-generator.
18-lines-request-generator.py
#!/usr/bin/env python3.7
import aiohttp
import asyncio
MAXREQ = 500
MAXTHREAD = 50
URL = 'https://google.com'
g_thread_limit = asyncio.Semaphore(MAXTHREAD)
async def worker(session):
async with session.get(URL) as response:
await response.read()
async def run(worker, *argv):
async with g_thread_limit:
await worker(*argv)
async def main():
async with aiohttp.ClientSession() as session:
await asyncio.gather(*[run(worker, session) for _ in range(MAXREQ)])
if __name__ == '__main__':
# Don't use asyncio.run() - it produces a lot of errors on exit.
asyncio.get_event_loop().run_until_complete(main())
See Implementation Notes in the annex below.
1 Line: The Most Important One
A lot of things happens at the following line:
await asyncio.gather(*[run(worker, session) for _ in range(MAXREQ)])
- coroutine
worker()contains a logic to send and receive HTTP(S) requests usingaiohttpsession; - coroutine
run()limits the number of consequently running workers using the semaphore (we can think about it as a about a thread pool but the threads are not the real ones); - generator
[]creates a big number of coroutines (MAXREQ) in order to utilize cooperative multitasking; asyncio.gather()schedules coroutines as tasks and waits until their completion.
Performance To Expect
Don't expect 1 million requests per second on your personal device. No. On practice, it's more realistic to expect thousands of requests per minute, at most, for the case of GET/POST requests of the application layer (layer 7 of the OSI model) with post-processing of responses. And it is only in the case of the most optimal resource utilization.
Let me show you why:
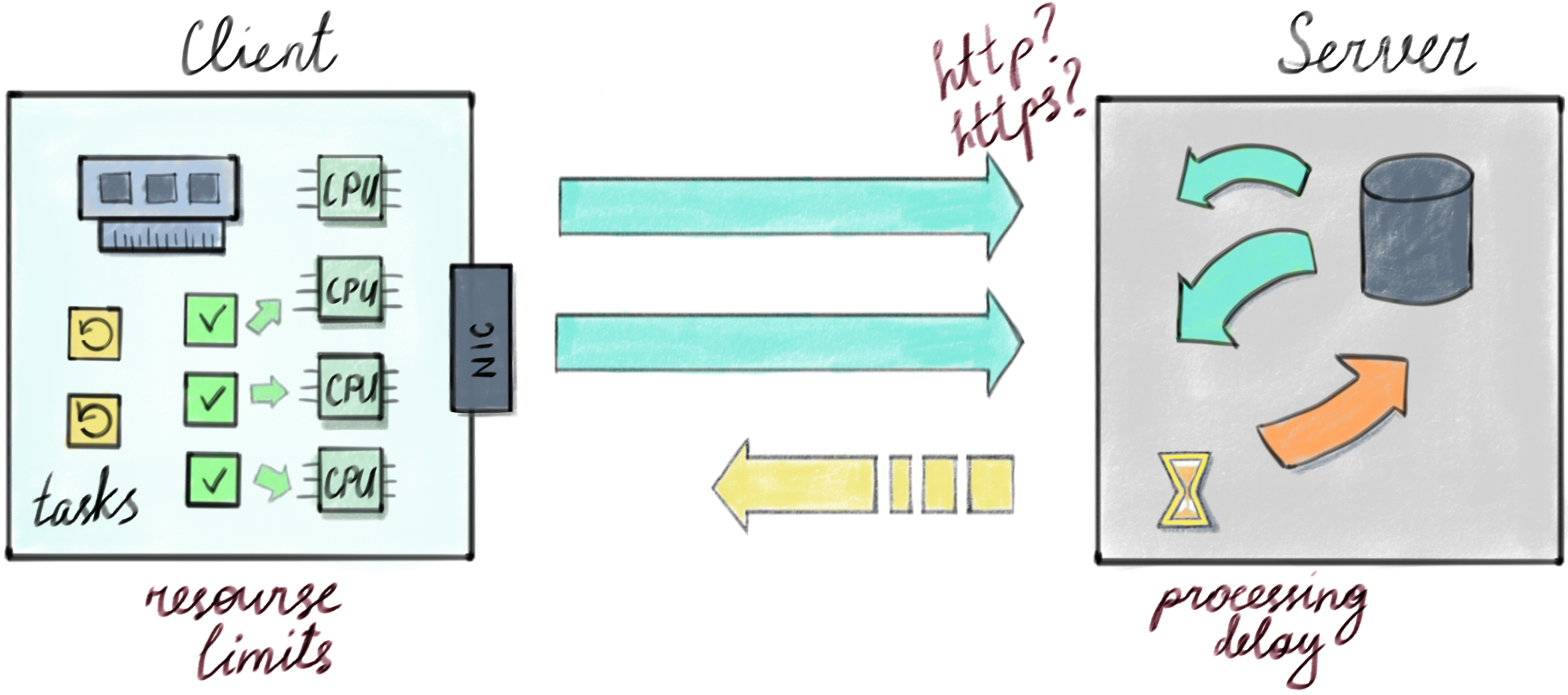
Client limits: If a client is going to post-process each request, a lot of sockets (file descriptors) should be created and held in the memory. The context for each connection is held in the memory as well. Then if a server doesn't return response back for too long, the client ends up with a limited count of open connections (e.g. 500-2000) not able to generate more requests. Also the client is not able to prepare and to process many requests concurrently, it is limited to CPU count.
Server limits: A server is not able to respond immediately, it needs to finish TLS handshake in a case of https, where cryptographic manipulations extensively utilize a processor time, the server needs to spend a time to analyze a request and to get data from database. Meanwhile the client is waiting.
In order to maximize a frequency of client requests you basically need three things:
- cooperative multitasking (
asyncio) - connection pool (
aiohttp) - concurrency limit (
g_thread_limit)
Let's go back to the magic line:
await asyncio.gather(*[run(worker, session) for _ in range(MAXREQ)])
1. Cooperative Multitasking (asyncio)
asyncio is here to hit the limit of computer's hardware and resources.
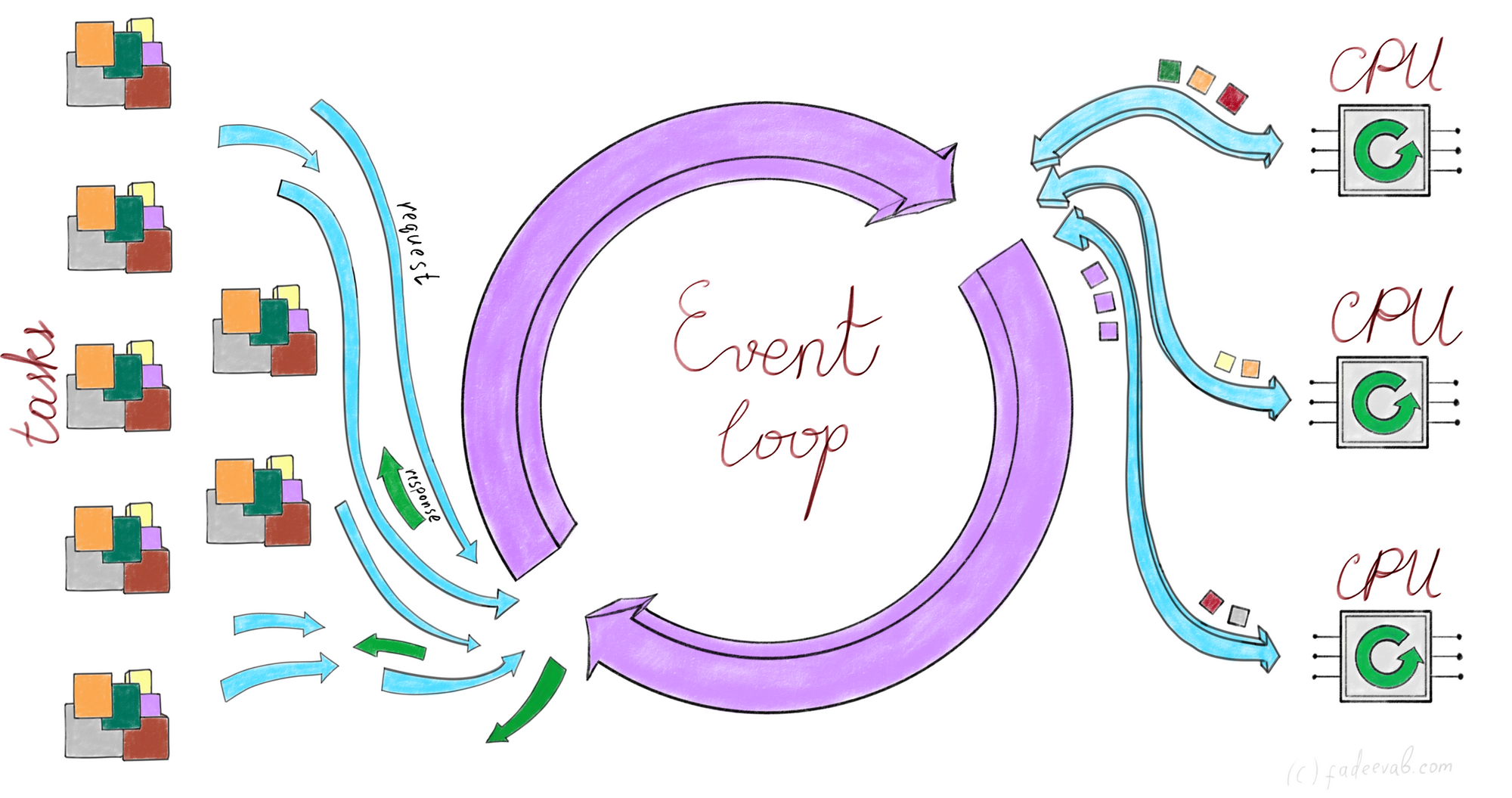
Event loop is a single non-blocking thread that tries to figure out how to carry out 1 million requests on client's 4 CPU cores through a single network card.
On the right side of the image, you can see a limited count of physical CPUs.
On the left side of the image, there are tasks that our program desires to do:
- to send 1 request and to get 1 response: it is a 1 task;
- to send 1000 requests and to get 1000 responses: it is 1000 tasks which could be parallelized.
Concretely in Python a single task can be represented by async coroutine ("worker()" in my example) consisted of a bunch of await blocks.
How to execute 1000 tasks on 4-8 CPU cores in the most effective way?
Whenever a coroutine "stucks" awaiting for a server response, the event loop of asyncio pauses that coroutine, pulling one from CPU execution to the memory, and then asyncio schedules another coroutine on CPU core. The processor never sleeps, and the event loop fills the gaps of awaiting events.
2. Connection Pool (aiohttp)
If to generate multiple requests without any optimization, then a huge amount of CPU time of the client is being consumed to finalize old connections in order to establish the new ones: one TLS handshake per each upcoming request. A TLS handshake is a pretty consuming operation. Whenever connection is closed, a TLS handshake must be carried out again to open a new connection.
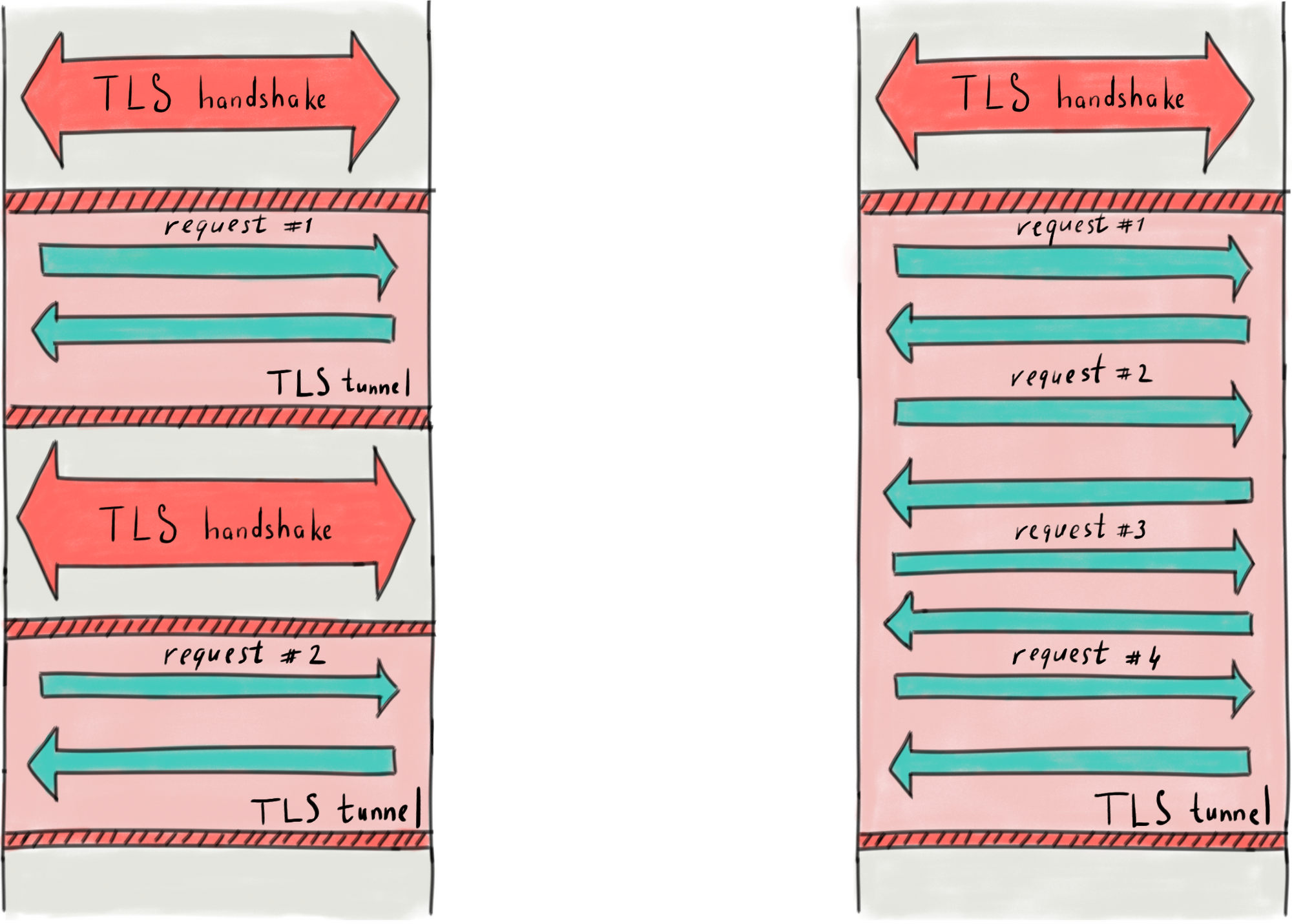
To increase a frequency of requests a TLS tunnel should be reused for multiple requests.
Connection pool keeps as many as possible open TLS connections. aiohttp opens a new connection and holds the connection as long as necessary. Upcoming requests load the pool evenly and go to the server via reused TLS tunnels. Each open connection means an open socket (file descriptor) and a context in the memory.
aiohttp holds about 100 connections in the connection pool by default.
3. Concurrency Limit
Everything is nice until you're going to send a million requests (setting up the parameter MAXREQ = 1000000 in the example above). In this case the event loop just blows up trying to handle million tasks (coroutines) all together. Generator [] creates a million coroutines, and the event loop tries to carry out literally each GET/POST connection request uploading the connection pool of aiohttp. Some requests are being processed quickly, some of them not. Because the server doesn't respond immediately a lot of memory is consumed to hold incomplete coroutines (their context and file descriptors). Finally your program crashes.
What we are going to do is to wait when the concurrency limit is reached.
g_thread_limit = asyncio.Semaphore(MAXTHREAD)
...
async with g_thread_limit:
await worker(*argv)I like to think about this as about a thread pool though technically it's not.
Shortly, the connection pool optimizes the potential amount of CPU cycles for TLS handshakes, the event loop optimizes the overall CPU utilization, and the concurrency limit optimizes the amount of workload that falls on the event loop itself.
Performance Measurements
500 requests (TOTALREQUESTS = 500)
$ time ./aiohttp-request-generator.py
real 0m3.701s
5000 requests (TOTALREQUESTS = 5000)
$ time ./aiohttp-request-generator.py
real 0m25.393s
500 requests with only 1 thread
I don't provide a code example here, I just used 1 coroutine and for _ in range(500) in the worker(). You can see how slower it is.
$ time ./aiohttp-request-generator.py
real 4m0.640s
Conclusion: 5000 requests per 25 seconds at most.
Implementation Notes
- You could see more complex solutions with semaphores and different fancy coroutine configurations, but seems like
asyncioandaiohttpare pretty smart enough, so I can see comparable results during my experiments. - google.com acts as a test server, and because google.com is able to process 40000 requests per second, our 5000 requests per 25 seconds don't harm too much.
- I ignore the returning result as well as error handling for a sake of simplicity, so this example is easier to understand and test. Basically, Google quickly identifies the script as a robot, and the captcha is being returned constantly.
- If you add the real business logic to prepare the request and to process the response you should see increasing CPU consumption.
- This article had a title "14 Lines of the Powerful Request Generator with Python" before I added a conqurency limitation via semaphore trick, so +4 LOC has been added making the final script to be a complete and reliable template for any powerful concurrency client.