Reaching AI Limits (and Ending Up on StackOverflow Again)
Writing on StackOverflow still matters, just not really for humans, but rather for AI serving humans.
I use AI daily. It's cool. It boosts my productivity.
Until it doesn't.
Try searching "cast send blob" for how to send a blob transaction on an EVM chain with the cast tool. You'll find my self-answered StackOverflow post at the top.
That post exists for a dumb reason: AI failed me on a trivial edge case.
Once the article appeared publicly, Google indexed it, and now AI partially uses my wording from it.
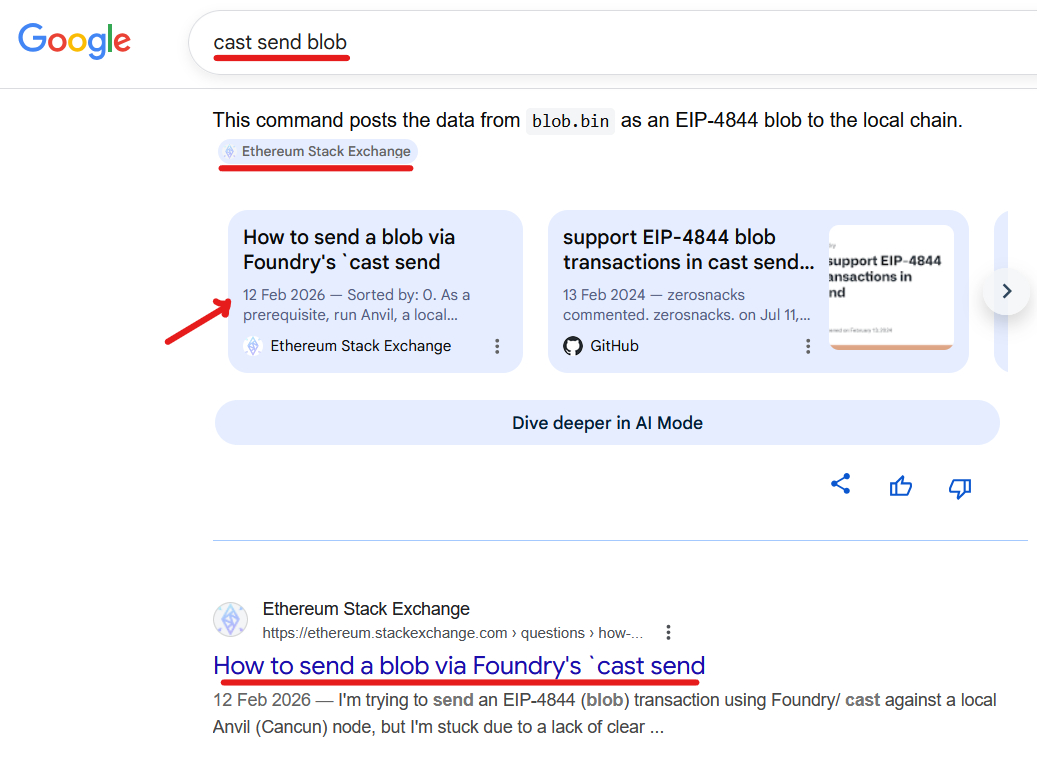
ethereum.stackexchange.com is a StackOverflow for the Ethereum-related topicsWhy does it matter?
I spent over an hour asking different models from different vendors how to do it. All models answered confidently - and all were wrong. They invented CLI flags, hallucinated parameters, and ignored requests for up-to-date documentation.
The real solution took minutes: I stopped prompting and read cast --help carefully.
And then I posted the self-answer.

It happened to me a few times, and it doesn't look random. LLMs fail similarly at edge cases.
The same thing happened with LogQL (a query language for Grafana Loki). After an hour or two of back-and-forth with AI, I gave up, opened the official docs, and composed a proper LogQL query myself.
It turns out both me and AI end up relying on "static" "non-conversational" public knowledge again.
LLMs are trained on public texts (particularly). When edge cases aren't documented, models don't slow down or say "I don't know". They struggle to find correct solutions and often hallucinate non-working answers overconfidently.
It bothers me because this failure mode is kind of invisible. If you already know the tool or the domain well, you'll notice when the answer smells wrong and go read the docs. If you don't, you might just keep trying random variations of a hallucinated solution, assuming you're the one missing something.
That's not great, especially for less popular tools, smaller projects, or newer ecosystems. It's wasted engineering time, and it adds up. The problem isn't that the models don't know. It's that they don't signal uncertainty. The former might be fixable - models can be taught to say "I don't know". The dependency on public knowledge is a different thing, though. It's not easy to "fix".
In a way, this brings us back to a familiar place: contributing to public knowledge still matters. And maybe not because of "open source values", but because AI depends on it.
It also changes the incentive structure a bit. Writing a good StackOverflow answer or a clear doc used to feel like helping other people. Now, it also feels like feeding the future models that everyone will use.
It's just that writing a self-answered article on StackOverflow matters not really for humans, but rather for AI serving humans.
Public knowledge still matters.
And now it matters to machines too.